
Why I've lost faith in p values, part 2
/In a previous post, I gave some examples showing that null hypothesis statistical testing (NHST) doesn’t actually tell us what we want to know. In practice, we want to know the probability that we are making a mistake when we conclude that an effect is present (i.e., we want to know the probability of a Type I error in the cases where p < .05). A genetics paper calls this the False Positive Report Probability (FPRP).
However, when we use NHST, we instead know the probability that we will get a Type I error when the null hypothesis is true. In other words, when the null hypothesis is true, we have a 5% chance of finding p < .05. But this 5% rate of false positives occurs only when the null hypothesis is actually true. We don’t usually know that the null hypothesis is true, and if we knew it, we wouldn't bother doing the experiment and we wouldn’t need statistics.
In reality, we want to know the false positive rate (Type I error rate) in a mixture of experiments in which the null is sometimes true and sometimes false. In other words, we want to know how often the null is true when p < .05. In one of the examples shown in the previous post, this probability (FPRP) was about 9%, and in another it was 47%. These examples differed in terms of statistical power (i.e., the probability that a real effect will be significant) and the probability that the alternative hypothesis is true [p(H1)].
The table below (Table 2 from the original post) shows the example with a 47% false positive rate. In this example, we take a set of 1000 experiments in which the alternative hypothesis is true in only 10% of experiments and the statistical power is 0.5. The box in yellow shows the False Positive Report Probability (FPRP). This is the probability that, in the set of experiments where we get a significant effect (p < .05), the null hypothesis is actually true. In this example, we have a 47% FPRP. In other words, nearly half of our “significant” effects are completely bogus.

The point of this example is not that any individual researcher actually has a 47% false positive rate. The point is that NHST doesn’t actually guarantee that our false positive rate is 5% (even when we assume there is no p-hacking, etc.). The actual false positive rate is unknown in real research, and it might be quite high for some types of studies. As a result, it is difficult to see why we should ever care about p values or use NHST.
In this follow-up post, I’d like to address some comments/questions I’ve gotten over social media and from the grad students and postdocs in my lab. I hope this clarifies some key aspects of the previous post. Here I will focus on 4 issues:
What happens with other combinations of statistical power and p(H1)? Can we solve this problem by increasing our statistical power?
Why use examples with 1000 experiments?
What happens when power and p(H1) vary across experiments?
What should we do about this problem?
If you don’t have time to read the whole blog, here are four take-home messages:
Even when power is high, the false positive rate is still very high when H1 is unlikely to be true. We can't "power our way" out of this problem.
However, when power is high (e.g., .9) and the hypothesis being tested is reasonably plausible, the actual rate of false positives is around 5%, so NHST may be reasonable in this situation
In most studies, we’re either not in this situation or we don’t know whether we’re in this situation, so NHST is still problematic in practice
The more surprising an effect, the more important it is to replicate
1. What happens with other combinations of statistical power and p(H1)? Can we solve this problem by increasing our statistical power?
My grad students and postdocs wanted to see the false positive rate for a broader set of conditions, so I made a little Excel spreadsheet (which you can download here). This spreadsheet can calculate the false positive rate (FPRP) for any combination of statistical power and p(H1). This spreadsheet also produces the following graph, which shows 100 different combinations of these two factors.
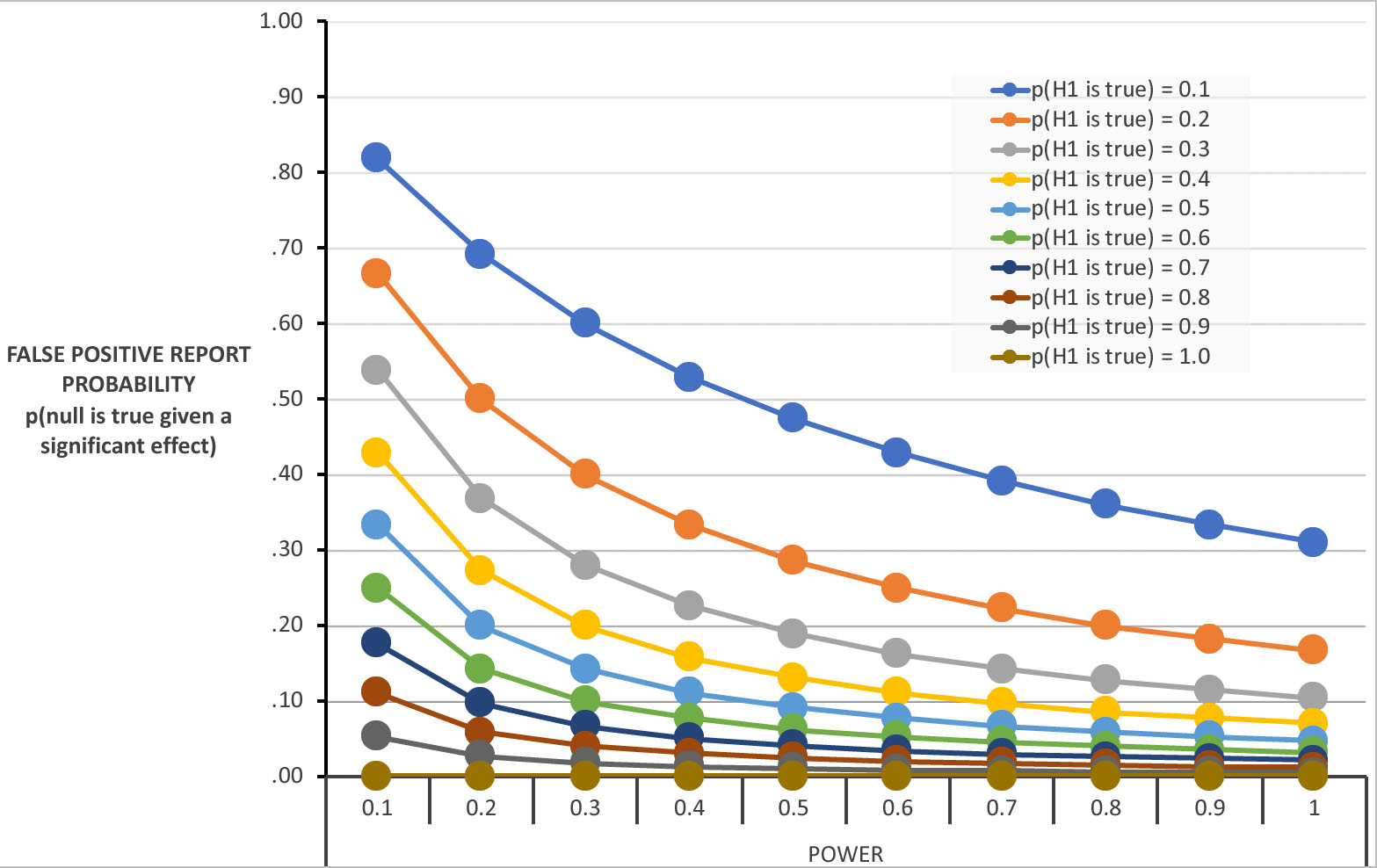
This figure shows the probability that you will falsely reject the null hypothesis (make a Type I error) given that you find a significant effect (p < .05) for a given combination of statistical power and likelihood that the alternative hypothesis is true. For example, if you look at the point where power = .5 and p(H1) = .1, you will see that the probability is .47. This is the example shown in the table above. Several interesting questions can be answered by looking at the pattern of false positive rates in this figure.
Can we solve this problem by increasing our statistical power? Take a look at the cases at the far right of the figure, where power = 1. Because power = 1, you have a 100% chance of finding a significant result if H1 is actually true. But even with 100% power, you have a fairly high chance of a Type I error if p(H1) is low. For example, if some of your experiments test really risky hypotheses, in which p(H1) is only 10%, you will have a false positive rate of over 30% in these experiments even if you have incredibly high power (e.g., because you have 1,000,000 participants in your study). The Type I error rate declines as power increases, so more power is a good thing. But we can’t “power our way out of this problem” when the probability of H1 is low.
Is the FPRP ever <= .05? The figure shows that we do have a false positive rate of <= .05 under some conditions. Specifically, when the alternative hypothesis is very likely to be true (e.g., p(H1) >= .9), our false positive rate is <= .05 no matter whether we have low or high power. When would p(H1) actually be this high? This might happen when your study includes a factor that is already known to have an effect (usually combined with some other factor). For example, imagine that you want to know if the Stroop effect is bigger in Group A than in Group B. This could be examined in a 2 x 2 design, with factors of Stroop compatibility (compatible versus incompatible) and Group (A versus B). p(H1) for the main effect of Stroop compatibility is nearly 1.0. In other words, this effect has been so consistently observed that you can be nearly certain that it is present in your experiment (whether or not it is actually statistically significant). [H1 for this effect could be false if you’ve made a programming error or created an unusual compatibility manipulation, so p(H1) might be only 0.98 instead of 1.0.] Because p(H1) is so high, it is incredibly unlikely that H1 is false and that you nonetheless found a significant main effect of compatibility (which is what it means to have a false positive in this context). Cases where p(H1) is very high are not usually interesting — you don’t do an experiment like this to see if there is a Stroop effect; you do it to see if this effect differs across groups.
A more interesting case is when H1 is moderately likely to be true (e.g., p(H1) = .5) and our power is high (e.g., .9). In this case, our false positive rate is pretty close to .05. This is good news for NHST: As long as we are testing hypotheses that are reasonably plausible, and our power is high, our false positive rate is only around 5%.
This is the “sweet spot” for using NHST. And this probably characterizes a lot of research in some areas of psychology and neuroscience. Perhaps this is why the rate of replication for experiments in cognitive psychology is fairly reasonable (especially given that real effects may fail to replicate for a variety of reasons). Of course, the problem is that we can only guess the power of a given experiment and we really don’t know the probability that the alternative hypothesis is true. This makes it difficult for us to use NHST to control the probability that our statistically significant effects are bogus (null). In other words, although NHST works well for this particular situation, we never know whether we’re actually in this situation.
2. Why use examples with 1000 experiments?
The example shown in Table 2 may seem odd, because it shows what we would expect in a set of 1000 experiments. Why talk about 1000 experiments? Why not talk about what happens with a single experiment? Similarly, the Figure shows "probabilities" of false positives, but a hypothesis is either right or wrong. Why talk about probabilities?
The answer to these questions is that p values are useful only in telling you the long-run likelihood of making a Type I error in a large set of experiments. P values do not represent the probability of a Type I error in a given experiment. (This point has been made many times before, but it's worth repeating.)
NHST is a heuristic that aims to minimize the proportion of experiments in which we make a Type I error (falsely reject the null hypothesis). So, the only way to talk about p values is to talk about what happens in a large set of experiments. This can be the set of experiments that are submitted to a given journal, the set of experiments that use a particular method, the set of experiments that you run in your lifetime, the set of experiments you read about in a particular journal, the set of experiments on a given topic, etc. For any of these classes of studies, NHST is designed to give us a heuristic for minimizing the proportion of false positives (Type I errors) across a large number of experiments. My examples use 1000 experiments simply because this is a reasonably large, round number.
We’d like the probability of a Type I error in any given set of experiments to be ~5%, but this is not what NHST actually gives us. NHST guarantees a 5% error rate only in the experiments in which the null hypothesis is actually true. But this is not what we want to know. We want to know how often we’ll have a false positive across a set of experiments in which the null is sometimes true and sometimes false. And we mainly care about our error rate when we find a significant effect (because these are the effects that, in reality, we will be able to publish). In other words, we want to know the probability that the null hypothesis is true in the set of experiments in which we get a significant effect [which we can represent as a conditional probability: p(null | significant effect); this is the FPRP]. Instead, NHST gives us the probability that we will get a significant effect when the null is true [p(significant effect | null)]. These seem like they’re very similar, but the example above shows that they can be wildly different. In this example, the probability that we care about [p(null | significant effect)] is .47, whereas the probability that NHST gives us [p(significant effect | null)] is .05.
3. What happens when power and p(H1) vary across experiments?
For each of the individual points shown in the figure above, we have a fixed and known statistical power along with a fixed and known probability that the alternative hypothesis is true (p(H1). However, we don’t actually know these values in real research. We might have a guess about statistical power (but only a guess because power calculations require knowing the true effect size, which we never know with any certainty). We don’t usually have any basis (other than intuition) for knowing the probability that the alternative hypothesis is true in a given set of experiments. So, why should we care about examples with a specific level of power and a specific p(H1)?
Here’s one reason: Without knowing these, we can’t know the actual probability of a false positive (the FPRP, p(null is true | significant effect)). As a result, unless you know your power and p(H1), you don’t know what false positive rate to expect. And if you don’t know what false positive rate to expect, what’s the point of using NHST? So, if you find it strange that we are assuming a specific power and p(H1) in these examples, then you should find it strange that we regularly use NHST (because NHST doesn’t tell us the actual false positive rate unless we know these things).
The purpose of examples like the one shown above is that they can tell you what might happen for specific classes of experiments. For example, when you see a paper in which the result seems counterintuitive (i.e., unlikely to be true given everything you know), this experiment falls into a class in which p(H1) is low and the probability of a false positive is therefore high. And if you can see that the data are noisy, then the study probably has low power, and this also tends to increase the probability of a false positive. So, even though you never know the actual power and p(H1), you can probably make reasonable guesses in some cases.
Most real research consists of a mixture of different power levels and p(H1) levels. This makes it even harder to know the effective false positive rate, which is one more reason to be skeptical of NHST.
4. What should we do about this problem?
I ended the previous post with the advice that my graduate advisor, Steve Hillyard, liked to give: Replication is the best statistic. Here’s something else he told me on multiple occasions: The more important a result is, the more important it is for you to replicate it before publishing it. Given the false positive rates shown in the figure above, I would like to rephrase this as: The more surprising a result is, the more important it is to replicate the result before believing it.
In practice, a result can be surprising for at least two different reasons. First, it can be surprising because the effect is unlikely to be true. In other words, p(H1) is low. A widely discussed example of this is the hypothesis that people have extrasensory perception.
However, a result can also seem surprising because it’s hard to believe that our methods are sensitive enough to detect it. This is essentially saying that the power is low. For example, consider the hypothesis that breast-fed babies grow up to have higher IQs than bottle-fed babies. Personally, I think this hypothesis is likely to be true. However, the effect is likely to be small, there are many other factors that affect IQ, and there are many potential confounds that would need to be ruled out. As a result, it seems unlikely that this effect could be detected in a well-controlled study with a realistic number of participants.
For both of these classes of surprising results (i.e., low p(H1) and low power), the false positive rate is high. So, when a statistically significant result seems surprising for either reason, you shouldn’t believe it until you see a replication (and preferably a preregistered replication). Replications are easy in some areas of research, and you should expect to see replications reported within a given paper in these areas (but see this blog post by Uli Schimmackfor reasons to be skeptical when the p value for every replication is barely below .05). Replications are much more difficult in other areas, but you should still be cautious about surprising or low-powered results in those areas.